CJARS works to ensure that all of its data are acquired through transparent and legitimate means. CJARS complies with both the requirements established by the University of Michigan Institutional Review Board and the U.S. Computer Fraud and Abuse Act (CFAA). This page outlines the workflow for developing web scrapers in accordance with the CJARS standards.
Scraping target criteria
The two factors that determine whether an agency’s website is “scrapeable” are its structure and security measures in place. Any agency that provides public access to their offender or criminal court data via (i) Application Programming Interfaces (APIs), (ii) direct downloads, or (iii) search forms is considered for web scraping. Agencies who provide subscription services or bulk purchase agreements are reviewed by a project manager or the principal investigator for acquisition appraisal. Agency websites using CAPTCHA or other security measures to prevent access by robots or non-human entities are not targeted; this would be a direct violation of website terms of use. Instead, data from such agencies should be acquired through a public records request or a data use agreement with the agency.
Scraping practice guidelines
All project web crawlers must conform to specific guidelines to ensure scraping efforts do not jeopardize other data collection efforts or CJARS overall. To ensure compliance with the Access Provision laid out in the CFAA, scraping efforts must consider both a website’s terms of service (ToS) as well as the privacy policy of using personal information. Although ToS typically contains brief disclaimers, some of the more scraper-friendly agencies may also share additional guidelines specifically pertaining to scraping, such as when to run a scraper. Violating ToS can expose the project and the university to legal liabilities and reputational concerns. Therefore, reviewing ToS carefully is critical to ensure CJARS avoids improper data collection behavior.
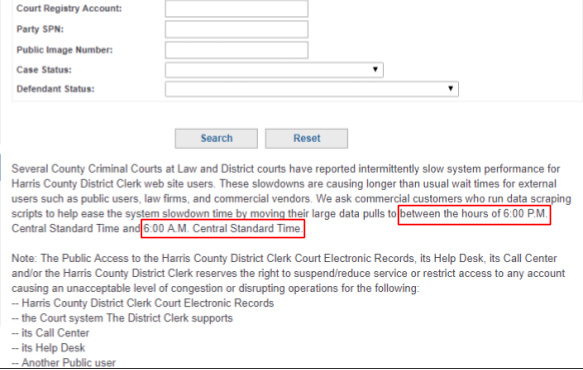
In addition, the robots exclusion protocol (robots.txt) provides instructions about the listed directories of a website to robots, an automated program for harvesting web data by emulating human behavior. The figure below provides an example of such a file. From these text files, the only field that will be singled out in this document is the Crawl-delay field for rate limiting crawl requests. As an example, if an agency’s robots.txt has Crawl-delay: 10, then for each interaction the crawler makes with the website that causes the page to refresh or reload, the crawler should wait at least 10 seconds before proceeding with the next task. For websites that do not explicitly specify a rate limiter, the default strategy should be to use the WebDriverWait function from the selenium.webdriver.support.ui package to wait up to 30 seconds for an HTML element to load.
To avoid denial of service, IP blocking, and thereby jeopardizing data use negotiations with an agency, CJARS limits the number of threads (or workers) when running a crawler in parallelization or distributed queues. A crawler can be assigned a maximum of four threads out of consideration for the CJARS scraper server’s resource constraints as well as the target’s capacity constraints. If four concurrent threads are causing target servers to slow and potentially crash, the number of concurrent threads should be reduced as needed. Under no circumstance should a scraper be repeatedly launched against a target if the script consistently leads to target server crash.
Documentation and data provenance
CJARS is required to provide documentation of legal provenance for all data brought to the U.S. Census Bureau. To satisfy these requirements, the crawler should archive the following files within each dataset’s provenance directories:
- Robots exclusion protocol (robots.txt)
- If there is no robots.txt, save the contents of the page as robots_404.txt.
- Screenshot of source webpage (PDF or PNG)
- Perma.cc link of source (HTML page)
- If the main page does not contain ToS information, a separate Perma.cc link should be created for the page with ToS details.
Perma.cc provides a permanent third-party hosted snapshot of the ToS when scraping is launched. This important documentation serves as proof that our collection efforts were not improper even if ToS are modified at a future date by a target site.
When a website also provides a data dictionary, this information should also be saved in the documentation folder for future reference.